그냥 ChatGPT 무료 버전을 사용하면 되지만, 다양한 방식으로 활용하기 위해서는 api를 사용하여 내부 로직을 바꾸거나, llama와 같은 언어 모델을 ollama 백엔드 서버에 올려 사용하거나, 혹은 Hugging Face에서 받아온 모델을 사용할 수 있을 것이다. 이를 편리하게 해주는 웹 프레임워크인 open-webui를 이용하여 온디바이스 LLM chatbot 환경을 구축해 보자!
1. ollama
순서를 무조건 이렇게 할 필요는 없지만, 먼저 ollama를 설치하고, 여러 언어 모델들을 다운로드하여 CLI 환경에서 작동시켜 보자.
GitHub - ollama/ollama: Get up and running with Llama 3.3, Mistral, Gemma 2, and other large language models.
Get up and running with Llama 3.3, Mistral, Gemma 2, and other large language models. - ollama/ollama
github.com
위 Github 주소에 들어가 다운로드하거나, 만약 Homebrew가 설치되어 있다면,
brew install ollama
터미널에 위와 같은 명령어를 통해 ollama를 다운로드할 수 있다.
언어모델 선택

현재까지 ollama에서 제공하는 언어 모델은 위와 같다. ollama에서는 7B model에 8 GB, 13B model에 16 GB, 그리고 33B model에 32 GB의 램 사양을 권장하고 있다. GPU 가속도 안되고, 램도 16 GB 밖에 안 되는 입장이기에 Llama3.1:8b, Llama3.2:1b, 그리고 Llama3.2:3b 정도를 설치해 본다.
Ollama
Get up and running with large language models.
ollama.com
직접 원하는 모델을 위 사이트에서 다운로드할 수도 있지만,
ollama serve
모델 연산을 하는 ollama 백엔드 서버를 열고, 다른 터미널 창을 열어서 (cmd + n)
ollama run llama3.1:8b
ollama run llama3.2:1b
ollama run llama3.2:3b
위와 같은 명령어를 주어 그냥 실행시키면, 해당 모델이 없는 경우에 알아서 다운로드를 한 후에 실행시켜 준다. 나중 가서 로컬 머신에 깔려 있는 ollama 지원 언어 모델이 뭔지 알고 싶다면,
ollama list
위 명령어를 통해 확인해 볼 수 있다.

이로써 원하는 모델들을 모두 다운로드해 보았다. 이제 실행 방법은 간단하다.
ollama run [모델 이름]
위와 같은 명령어를 통해 실행시키면 터미널 환경에서 챗봇 사용이 가능하다. 채팅을 그만하고 싶으면 /bye 명령어를 입력하거나 ctrl + d를 사용하면 된다.

사용해 보면 알겠지만, 성능은 영어 대화에서만 준수한 편이다. 파라미터가 1b나 3b라니, 이 정도면 매우 경량화를 잘 한 모델로 볼 수 있지만, 한국인의 입장에서는 Hugging Face에서 한국어 특화 모델을 사용하는 편이 훨씬 나을 것이다.
2. open-webui
이제 CLI 환경에서만 작동하던 ollama의 정식 언어 모델들을 ChatGPT 같은 웹사이트에서 실행시켜 보자. 이렇게 한다면 보기에도 편하고 주제 별로 정리도 되는, 말 그대로 나만의 ChatGPT (스카치테이프처럼 고유 명사가 돼버린 것 같다.)를 만들 수 있다.
GitHub - open-webui/open-webui: User-friendly AI Interface (Supports Ollama, OpenAI API, ...)
User-friendly AI Interface (Supports Ollama, OpenAI API, ...) - open-webui/open-webui
github.com
위 Github 주소에 가면 자세한 설명을 확인할 수 있다.
pip install open-webui
위와 같은 명령어를 입력하면 open-webui가 설치된다. 혹시 에러가 발생한다면, 그건 open-webui가 python 3.11 버전 이상을 지원하기 때문이다! 그렇다고 모든 환경에서 버전을 변경하면 안 되니, open-webui를 실행하기 위한 공간만 별도로 마련해 보자.
python --version
ls /usr/bin/python* /usr/local/bin/python* | grep python
현재 파이썬 버전과 로컬 머신에 깔려 있는 파이썬들을 확인하는 명령어이다.
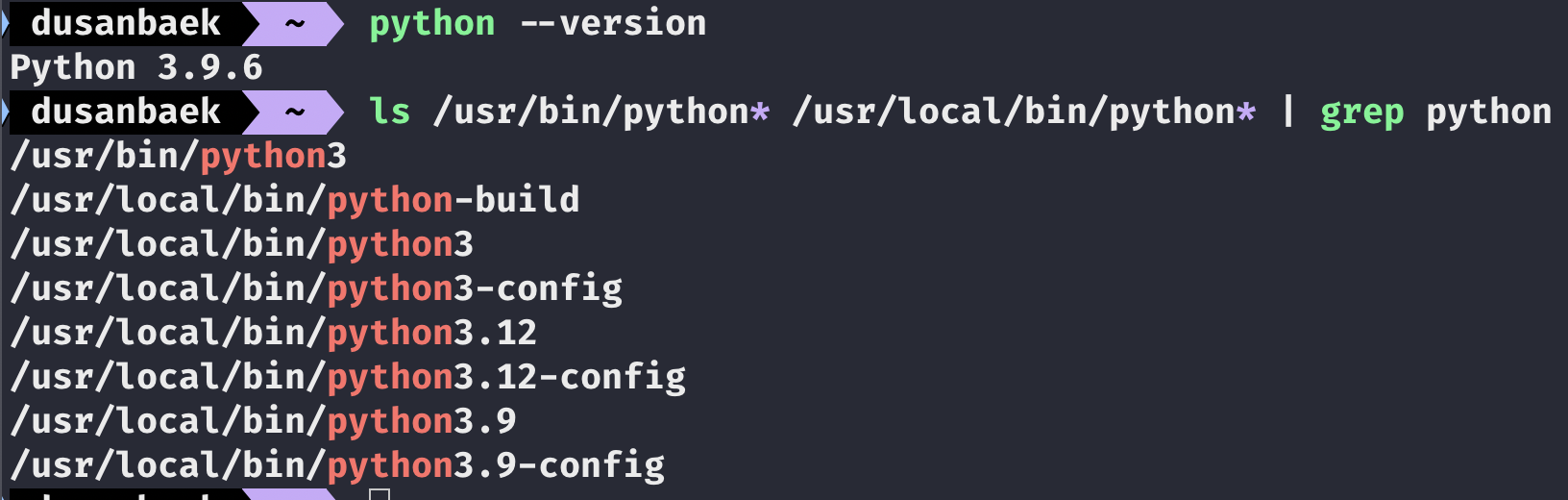
와따 많이도 깔려 있네... 현재 파이썬 버전이 3.9대라서 안 되나 보다. 그럼 3.11 이상을 이용하는 private 한 디렉터리를 만들어 보자! 이를 위해서는 pyenv라는 바이썬 버전 관리 도구를 이용해야 한다.
curl https://pyenv.run | bash
이렇게 설치를 해주고,
pyenv versions
어느 버전이 있는지 확인해 보면,
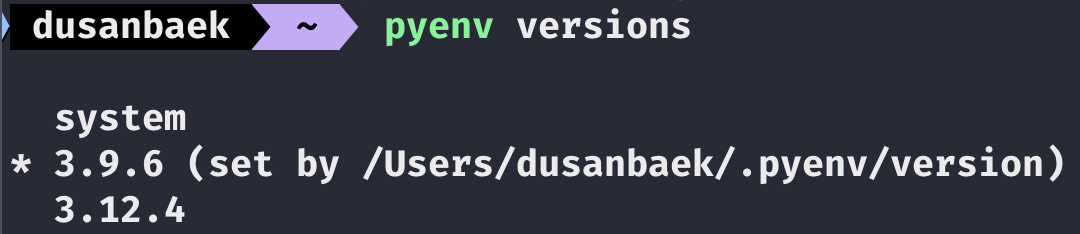
두 버전이 있고, 현재 상태는 3.9.6 임을 알 수 있다. 이건 그대로 두고
mkdir llamaWeb
cd llamaWeb
llamaWeb이라는 디렉터리를 만들자. 그리고 이 디렉터리에서는 파이썬 3.11 이상의 환경으로 세팅하면 된다. 이렇게 하면 전역적으로는 python 3.9.6 버전을 사용하되 특정 디렉터리에서만 원하는 버전의 python 환경으로 세팅이 가능하다.
pyenv install 3.12 (이미 있으면 생략)
pyenv local 3.12
python --version
해당 디렉터리에서 위 명령어를 차례대로 실행시켜 주어, 이 디렉터리 내에서만 파이썬 환경을 3.12대로 맞춰주었다. 그리고 다시 open-webui를 설치해 주면 정상적으로 설치가 될 것이다! 이어서
open-webui serve
위 명령어를 통해 웹서버를 열고, http://localhost:8080 주소를 입력해 주면,
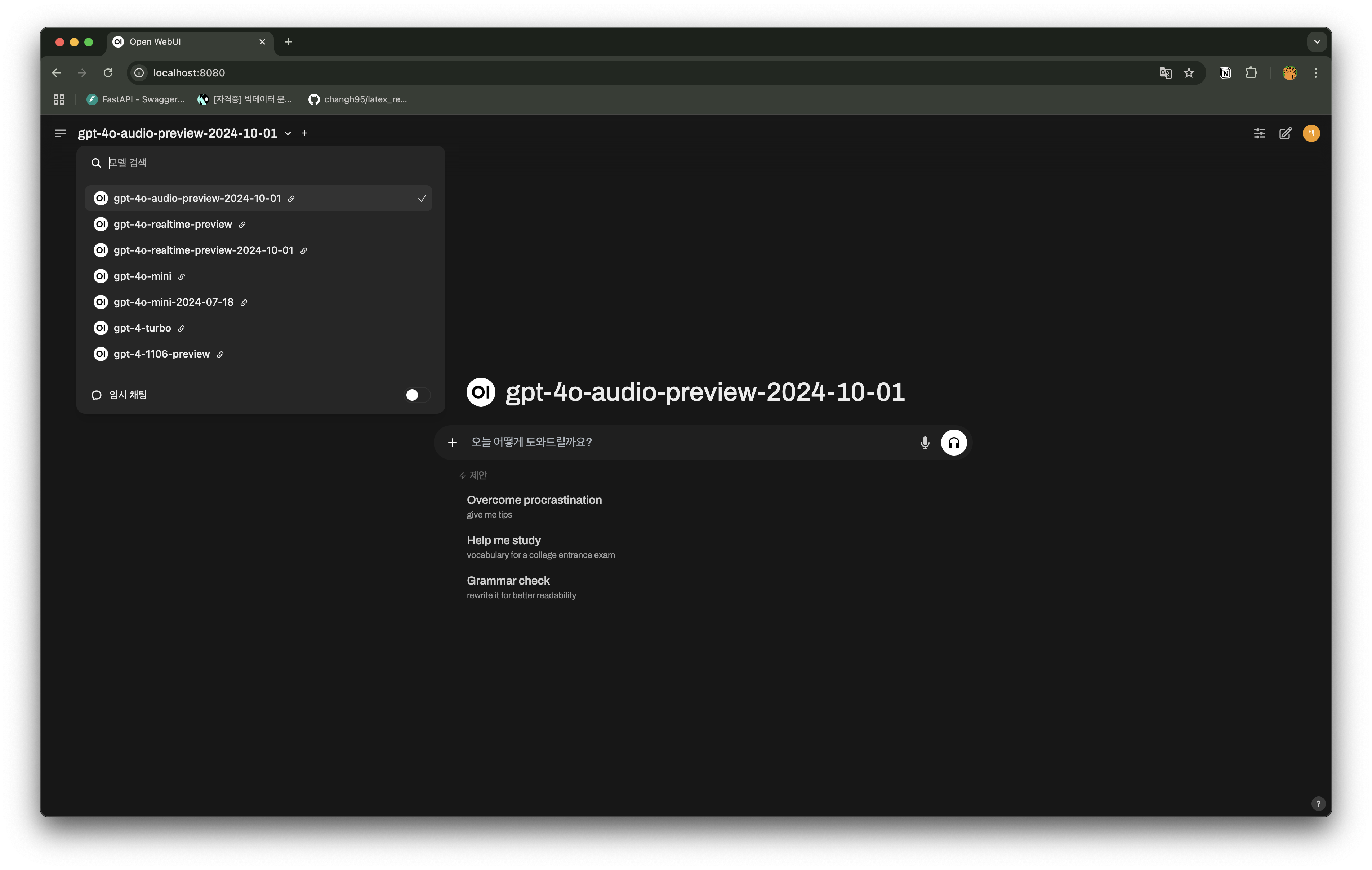
실행이 된다! 나의 경우 로컬 머신에 OpenAI api key를 환경 변수로 지정해 두었기에 gpt 모델들도 사용이 가능하다 (물론 돈이 나간다.). 위 모델 리스트의 스크롤을 내리다 보면,
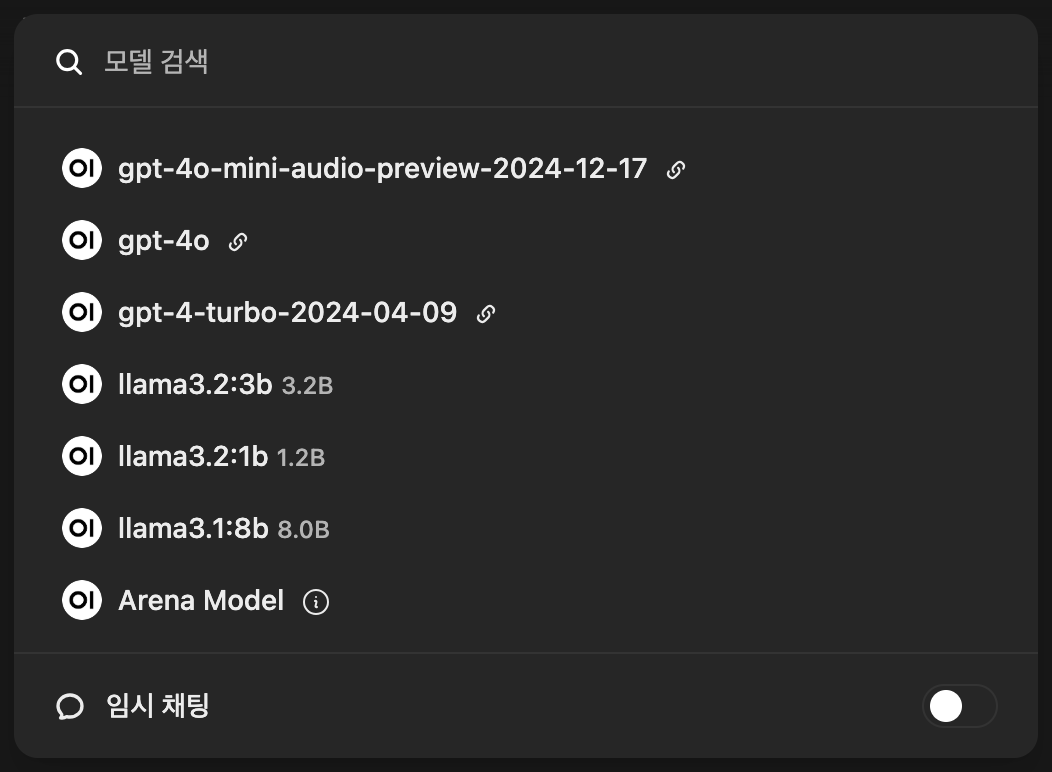
이렇게 앞서 실행해 두었던 llama 모델들을 확인할 수 있다! 이제 클릭해서 사용하면 된다 :)
CLI랑 성능은 그대로니 큰 기대는 말 것. 간혹 가다 에러가 발생하는 경우가 있는데, 이는 ollama serve가 되어 있지 않아서다. ollama를 통해 제공되는 언어 모델들을 사용하려면 무조건 ollama serve를 통해 연산에 사용되는 백엔드 서버를 오픈해 두어야만 사용이 가능하다. OpenAI api key를 이용하거나, Hugging Face에서 튜닝된 언어 모델들을 다운로드하여 사용한다면, open-webui만 열어두고도 사용이 가능하다.
여전히 바보는 바보다.
'AI' 카테고리의 다른 글
| [LLM] Groq: LPU 기반으로 대규모 AI 모델 (LLaMA70b, Gemma2-9b) 경험해 보기 - Free API Key 발급, Langchain 예제 (1) | 2025.01.24 |
|---|---|
| [LLM] RAG 개선하기 (3) - 바이 인코더 + 교차 인코더 (0) | 2024.11.26 |
| [LLM] RAG 개선하기 (2) - 임베딩 모델 미세 조정하기 (Fine-Tuning) (0) | 2024.11.25 |
| [LLM] RAG 개선하기 (1) - 언어 모델을 임베딩 모델로 만들기 (0) | 2024.11.24 |
| [LLM] 임베딩 모델로 데이터 의미 압축하기 (3) - 의미, 키워드, 하이브리드 검색 (2) | 2024.11.19 |