[LLM] 임베딩 모델로 데이터 의미 압축하기 (1) - 텍스트 임베딩 이해하기
컴퓨터가 자연어를 이해하려면 텍스트를 숫자로 바꿔야 하는데, 이 과정에서 '임베딩'이라는 방식이 쓰인다. 오늘은 텍스트를 숫자로 바꾸는 다양한 방법과 그 변천사를 알아보고, 각각의 방식
dusanbaek.tistory.com
지난 시간에 이어 이번엔 문장 임베딩에 대해 알아보자. 결국에 문장 단위로 입력에 넣어서 임베딩을 진행하는데, 여러 방식 중 하나는 트랜스포머의 인코더 구조를 사용하는 것이다. 내 블로그에 트랜스포머의 구조를 설명해 놓았으니, 이를 참고하면 한 문장이 어떻게 임베딩 벡터로 변환되는지 이해할 수 있을 것이다. 두 문장이 주어졌을 때 두 문장이 얼마나 유사한지 구하는 두 방식을 알아보고, 실습을 통해 개념을 정립해 보자.
바이 인코더, 교차 인코더
텍스트를 임베딩할 때 사용하는 트랜스포머 인코더 구조의 대표 주자는 바로 BERT이다. 텍스트를 입력값으로 하여 BERT에 집어넣으면 이는 저차원의 임베딩 벡터로 변환이 된다. 두 문장의 유사도를 구하기 위해서는 두 가지 방법이 있는데, 하나는 바이 인코더 (bi-encoder) 그리고 다른 하나는 교차 인코더 (cross-encoder)이다.
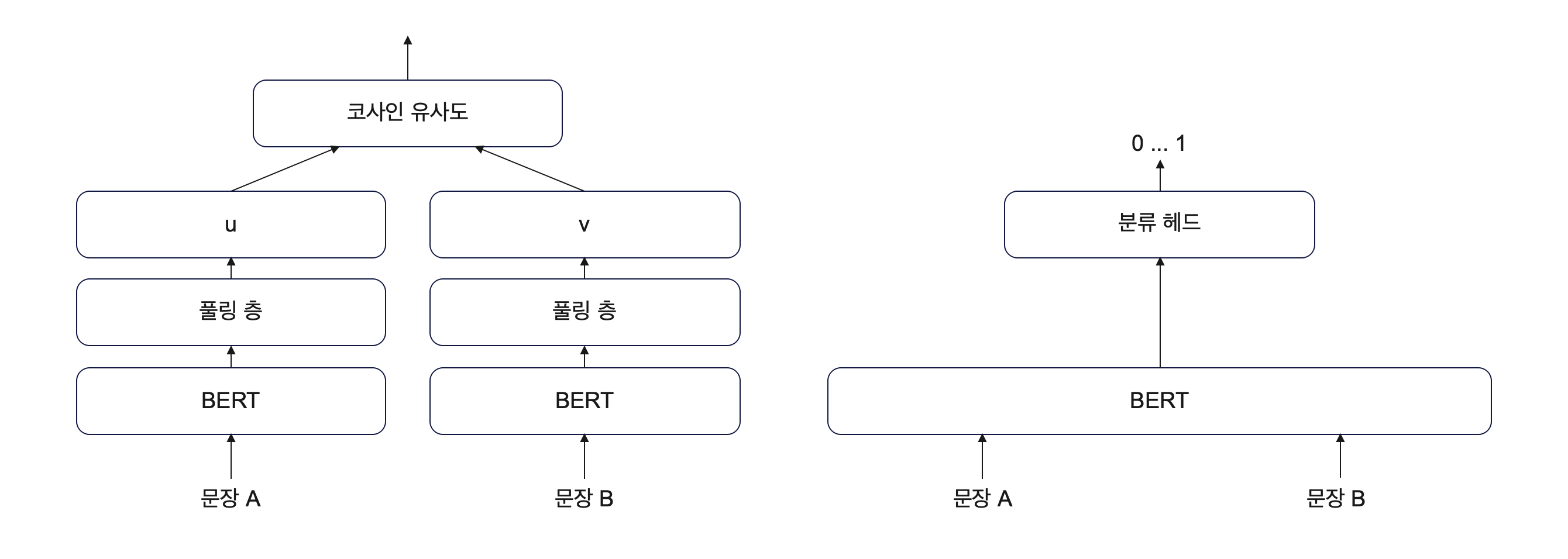
바이 인코더
매우 이해하기 쉬운 방식이다. 두 문장을 따로 BERT에 넣어 임베딩 벡터로 변환하여, 풀링을 통해 차원을 맞춰주고 코사인 유사도를 통해 비교한다.
교차 인코더
두 문장을 순차적으로 두고 합친 후에 한 BERT에 같이 넣는다. 그리고 두 문장 사이의 관계를 분류 헤드를 통해 0과 1 사이의 값으로 출력한다.
둘 다 장단점이 있다. 바이 인코더는 하나의 문장이 들어왔을 때 임베딩 변환을 완료하면, 다른 문장과의 코사인 유사도만 계산하면 되기 때문에 효율적이지만 교차 인코더만큼 두 문장의 상호작용을 고려하진 못한다. 교차 인코더는 반대로 어떤 문장에 대해 유사한 다른 문장이 뭐가 있는지 알아보기 위해서는 다른 문장의 개수만큼 연산을 해주어야 한다. 따라서 비효율적이지만 그만큼 두 문장 간 상호작용을 고려하기 좋다.
바이 인코더의 모델 구조
그래서 결국 효율이 높은 바이 인코더가 널리 사용되게 되었다. 이어서 모델 구조를 살펴보자.
from sentence_transformers import SentenceTransformer, models
# 사용할 BERT 모델
word_embedding_model = models.Transformer('klue/roberta-base')
# 풀링 층 차원 입력하기
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension())
# 두 모듈 결합하기
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
SentenceTransformer 라이브러리를 활용하여 BERT 모델의 구조를 자니는 roberta-base 모델을 불러온다. 풀링층도 선언해 주고, 마지막에 두 모델을 순차적으로 결합하여 한쪽의 바이 인코더 구조를 생성할 수 있었다.
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
모델 구조를 보면 위와 같다. 임베딩의 차원은 768이 되고, 이어서 세 가지 풀링 모드가 차례로 나오는데 기본 값으로 mean 방식이 True로 되어 있는 것을 확인할 수 있었다. 풀링 모드란 여러 토큰 벡터를 하나의 문장 벡터로 요약하는 것이다. CLS 모드는 첫 번째 토큰([CLS])의 임베딩을 사용하고, Mean 모드는 모든 토큰의 임베딩 평균값을 사용하며, Max 모드는 각 차원의 최댓값을 사용해 문장 벡터를 생성한다.
평균 모드
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0]
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1)
sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9)
return sum_embeddings / sum_mask
먼저 평균 모드다. 입력으로 모델의 출력값과 패딩 토큰의 위치를 받는다. model_output의 0번째 요소는 무엇인가? 이들의 차원은
[batch_size, seq_length, hidden_size]
이러하다. 하지만 attention_mask의 차원은
[batch_size, seq_length]
이므로 차원을 맞춰주기 위해 unsqueeze로 맨 끝 차원을 확장, 그리고 맨 끝 차원의 사이즈를 token_embeddings의 사이즈로 늘려준다. 이후에 두 텐서의 요소 곱을 통해 패딩 토큰이 0이 되는 부분을 날려주고, 두 번째 차원인 seq_length를 기준으로 더해준다. 이러한 방식을 거치고 나면, 두 번째 차원인 seq_length가 사라지면서
[batch_size, hidden_size]
만 남게 된다. 이것이 sum_embeddings가 되며 평균을 구하기 위해 전체 사이즈로 나누어줘야 하므로 input_masked_expanded도 마찬가지로 두 번째 차원인 seq_length를 기준으로 더해준다. 뒤에 min이라는 인자가 붙은 이유는 간혹 유효한 토큰이 없어서 sum_mask의 요소 중 하나가 0이 된다면 0으로 나눌 수 없기에 최솟값을 아주 작은 녀석으로 설정하여 계산의 안정성을 보장하기 위해서다.
최대 모드
def max_pooling(model_output, attention_mask):
token_embeddings = model_output[0]
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
token_embeddings[input_mask_expanded == 0] = -1e9
return torch.max(token_embeddings, 1)[0]
첫 두줄은 평균 모드와 동일하다. 이후 패딩 토큰이 0인 부분을 최솟값으로 설정하여 최댓값이 될 수 없게 바꾸고, 그중 가장 큰 값을 골라준다.
텍스트와 이미지 임베딩 해보기 with SentenceTransformers
이전 포스팅에서 결국 SentenceTransformer를 사용하게 될 것이라는 언급을 했었다. 이 라이브러리를 이용해서 세 문장의 유사도를 계산해 보고, 또 이미지 모델을 활용해서 두 이미지의 유사도도 비교해 보자.
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('snunlp/KR-SBERT-V40K-klueNLI-augSTS')
embs = model.encode(['잠이 안 옵니다',
'졸음이 옵니다',
'기차가 옵니다'])
cos_scores = util.cos_sim(embs, embs)
print(cos_scores)
위 코드는 이전 포스팅의 코드에서 단어가 문장으로 바뀐 것 외에 코드의 구조가 바뀐 것은 없다. 이 결과를 출력해 보면
warnings.warn(
tensor([[1.0000, 0.6410, 0.1887],
[0.6410, 1.0000, 0.2730],
[0.1887, 0.2730, 1.0000]])
위와 같다. 잠이 안 오는 상황과 졸음이 오는 상황이 높은 유사도를 보였고, 전혀 관련 없는 기차와는 낮은 유사도를 보임을 알 수 있다.
from PIL import Image
from sentence_transformers import SentenceTransformer, util
model = SentenceTransformer('clip-ViT-B-32')
img_embs = model.encode([Image.open('dog.jpg'), Image.open('cat.jpg')])
text_embs = model.encode(['A dog on grass', 'Brown cat on yellow background'])
cos_scores = util.cos_sim(img_embs, text_embs)
print(cos_scores)
이어서 볼 것은 텍스트와 이미지의 멀티 모달 모델을 이용하여 이미지와 텍스트의 유사도를 비교하는 실습이다. CLIP 모델은 이미지와 텍스트를 같은 벡터 공간으로 매핑하는 멀티모달 모델이다. 이를 통해 이미지 임베딩과 텍스트 임베딩이 동일한 공간에서 유사도를 비교할 수 있도록 설계되었다. 개와 고양이 이미지를 가져와 같은 디렉터리에 위치한 후 위 코드를 실행시켜 주자. 이미지와 텍스트를 임베딩한 후에 둘을 비교해 보면
tensor([[0.2771, 0.1509],
[0.2071, 0.3180]])
위와 같은 결과가 나온다! 이를 통해 개의 이미지는 개에 대한 설명과 유사하고, 고양이 이미지는 고양이에 대한 설명과 비교적 유사함을 확인할 수 있었다.
'AI' 카테고리의 다른 글
| [LLM] RAG 개선하기 (1) - 언어 모델을 임베딩 모델로 만들기 (0) | 2024.11.24 |
|---|---|
| [LLM] 임베딩 모델로 데이터 의미 압축하기 (3) - 의미, 키워드, 하이브리드 검색 (2) | 2024.11.19 |
| [LLM] 임베딩 모델로 데이터 의미 압축하기 (1) - 텍스트 임베딩 이해하기 (0) | 2024.11.16 |
| [LLM] 데이터를 검증하는 방식 알아보기 with NeMo-Guardrails (1) | 2024.11.14 |
| [LLM] LLM Cache로 효율성 확보하기 with ChromaDB (0) | 2024.11.13 |