

우리는 ChatGPT의 답변을 얼마나 신뢰할 수 있을까? ChatGPT 유료 멤버십을 사용한다면, 보통 ChatGPT 4o 모델을 사용할 테니 웬만한 질문에 대한 답변에서 할루시네이션 (hallucination) 이 일어날 가능성이 상대적으로 줄어든다. 이는 모델이 모르는 정보에 대해 외부 정보를 검색해서 나오는 데이터를 참고하여 답변하기 때문이다. 이 방식은 이후 설명할 RAG와 유사한 방식으로 작동된다.
RAG (Retrieval-Augmented Generation)
RAG는 한국말로 검색 증강 생성이다. 검색 증강 생성이란, LLM이 질문에 대한 답변을 확률에 기반한 생성에 집중할 뿐만 아니라 답변에 필요한 충분한 정보와 맥락을 제공하고 답변하도록 하는 방법이다. 말 그대로 검색을 통해 보충한 생성이라는 의미인 것이다. 앞서 말한 대로 최신 모델을 사용하면 해결되는 문제이지만, 모델이 좋을수록 높은 비용이 발생한다. 따라서 저비용의 언어 모델을 사용하면서도 높은 정확도를 유지하고 할루시네이션을 방지하려면 필요한 기능이다. 또 특정 데이터베이스만으로 범위를 좁혀서 특정 도메인에 특화된 지식을 학습시키지 않고도 자신에게 적합한 맞춤형 확장 챗봇을 만들 수 있다는 장점이 있다.
할루시네이션 (Hallucination)
from openai import OpenAI
import os
client = OpenAI(api_key= os.getenv("OPENAI_API_KEY"))
response = client.chat.completions.create(
model= "gpt-3.5-turbo",
messages= [
{
"role": "user",
"content": "뽀로로대학교에 다니는 핫츄핑에 대해 설명해 줘."
}
],
temperature= 1,
top_p= 1,
frequency_penalty= 0,
presence_penalty= 0
)
print(response.choices[0].message.content)
이전 포스팅을 통해 OpenAI API 사용법을 익혀보았다. 우리는 할루시네이션이 어떻게 일어나는지를 보기 위해 말도 안 되는 질문을 GPT-3.5-turbo 모델에게 물어보았다. 그랬더니 모델의 답변은 다음과 같다.
핫츄핑은 뽀로로대학교의 대표적인 학생 단체 중 하나로, 핫츄핑은 Hot-추억을 Ping하는 줄임말로서 학생들 간의 다양한 추억을 공유하고 소통하는 단체입니다. 핫츄핑은 다양한 학술, 문화, 체육 등의 활동을 통해 학생들에게 다양한 경험과 기회를 제공하며, 학교 생활을 더욱 풍부하고 유익하게 만들기 위해 다양한 노력을 기울이고 있습니다. 핫츄핑은 또한 학생들 간의 친목을 도모하고 새로운 인연을 만들어가는데도 큰 역할을 합니다. 뽀로로대학교 학생들에게는 꼭 가입해 보길 추천하는 단체 중 하나입니다.
이 세상에는 뽀로로대학교도 없고 하츄핑은 그곳에 다니지도 않는다. 하지만 확률에 기반한 문장 생성에서는 충분히 이러한 결과가 나올 수 있다. 그러면 같은 질문을 ChatGPT-4o에 해보자.
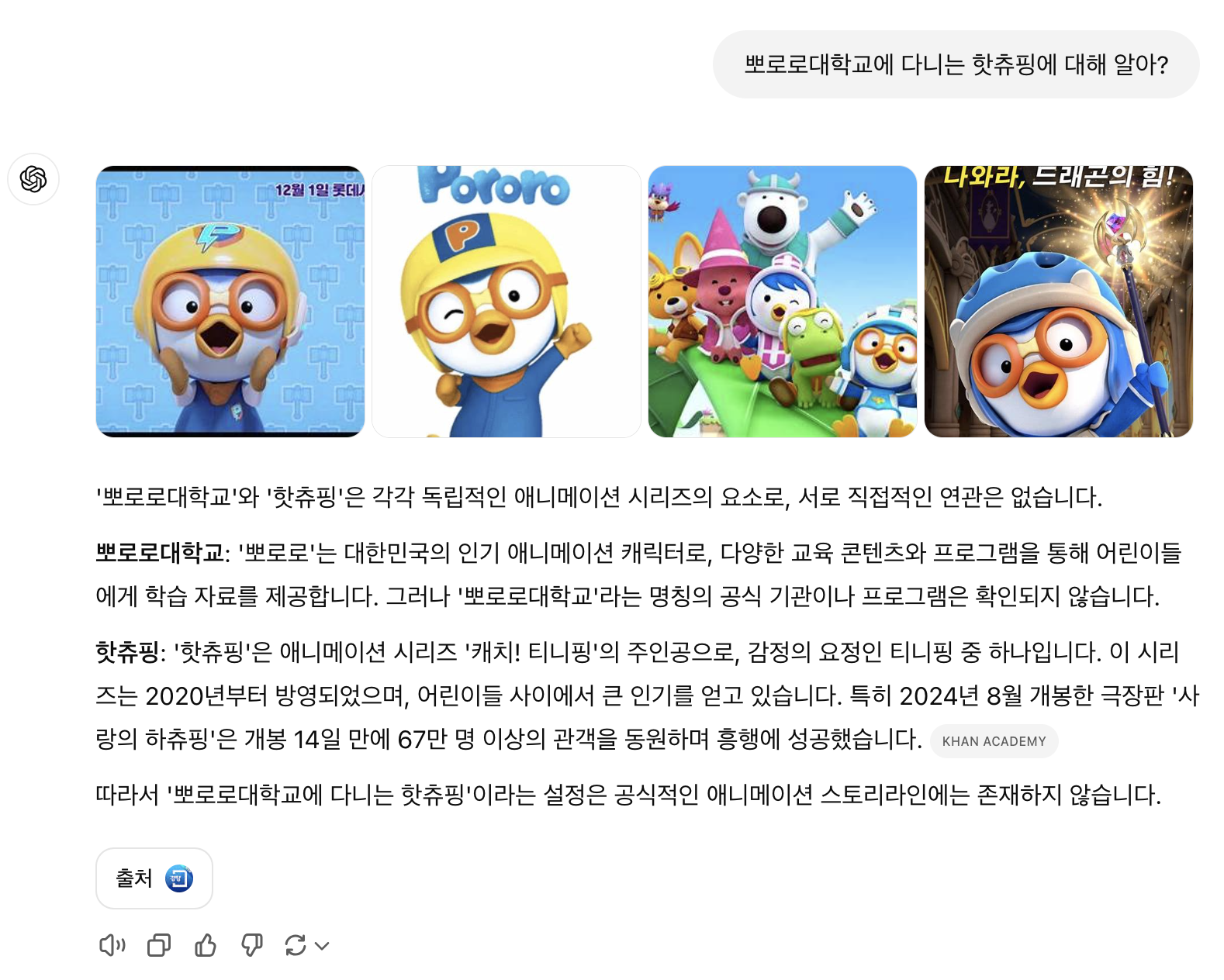
4o 모델은 질문에 대한 답을 찾기 위해 웹에 검색을 하고, 그로 인해 찾은 데이터를 참조하여 답변을 생성한다. 이를 통해 내가 원했던 '그런 학교는 존재하지 않는다'라는 답변을 얻을 수 있었다.
프롬프트로 해결하기
우리는 assistant로 실제 사실을 기반으로 하는 정보를 제공함으로써 할루시네이션을 방지할 수 있다.
response = client.chat.completions.create(
model= "gpt-3.5-turbo",
messages= [
{
"role": "assistant",
"content": "뽀로로대학교는 없습니다. 핫츄핑이라는 존재는 없습니다. 하츄핑입니다. 따라서 뽀로로대학교에 다니는 핫츄핑은 잘못된 표현입니다."
},
{
"role": "user",
"content": "뽀로로대학교에 다니는 핫츄핑에 대해 설명해 줘."
}
],
temperature= 1,
top_p= 1,
frequency_penalty= 0,
presence_penalty= 0
)
print(response.choices[0].message.content)
이런 식으로 프롬프트를 주면 나오는 결과는 다음과 같다.
죄송합니다. 뽀로로대학교는 실제로 존재하지 않는 가상의 대학이며, 핫츄핑이라는 존재 또한 현실에서는 존재하지 않습니다. 따라서 뽀로로대학교에 다니는 핫츄핑에 대해 설명드리기 어렵습니다. 더 이상 잘못된 정보를 제공하여 혼동을 드리지 않기 위해 정확한 정보를 제공할 수 있도록 노력하겠습니다. 어떤 다른 질문이 있으실까요?
하지만 우리가 비슷하거나 관련 있는 요청을 지속적으로 보내야 하는 상황이라면, 매번 이런 식으로 프롬프트를 주는 것은 비효율적이다. 따라서 우리는 모델이 필요한 정보가 담긴 데이터를 임베딩하여 벡터 데이터베이스화 하고, 요청 시에 임베딩된 데이터와의 유사도를 계산하여 가장 가까운 정보로 할루시네이션을 방지하는 답변을 얻을 수 있다. 이것이 바로 RAG의 근본적이 작동 원리다. 이어서 살펴보자.
벡터 데이터베이스로 해결하기
!pip install datasets llama-index==0.10.34
시작하기에 앞서 필요한 라이브러리를 다운로드하여 준다. dataset은 RAG에 사용할 실제 데이터셋을 가져오기 위해 필요하다. 라마 인덱스는 대표적인 LLM ochestration 라이브러리로, 유사한 텍스트 검색 및 생성하는 모든 과정을 수행할 수 있는 강력한 라이브러리이다.
데이터 불러오기
from datasets import load_dataset
dataset = load_dataset('klue', 'mrc', split='train')
dataset[0]
먼저 데이터셋을 받아온다. 예시로 사용할 데이터셋을 불러오고 첫 번째 데이터를 확인해 보면 다음과 같이 출력된다.
{'title': '제주도 장마 시작 … 중부는 이달 말부터',
'context': '올여름 장마가 17일 제주도에서 시작됐다. 서울 등 중부지방은 예년보다 사나흘 정도 늦은 이달 말께 장마가 시작될 전망이다.17일 기상청에 따르면 제주도 남쪽 먼바다에 있는 장마전선의 영향으로 이날 제주도 산간 및 내륙지역에 호우주의보가 내려지면서 곳곳에 100㎜에 육박하는 많은 비가 내렸다. 제주의 장마는 평년보다 2~3일, 지난해보다는 하루 일찍 시작됐다. 장마는 고온다습한 북태평양 기단과 한랭 습윤한 오호츠크해 기단이 만나 형성되는 장마전선에서 내리는 비를 뜻한다.장마전선은 18일 제주도 먼 남쪽 해상으로 내려갔다가 20일께 다시 북상해 전남 남해안까지 영향을 줄 것으로 보인다. 이에 따라 20~21일 남부지방에도 예년보다 사흘 정도 장마가 일찍 찾아올 전망이다. 그러나 장마전선을 밀어올리는 북태평양 고기압 세력이 약해 서울 등 중부지방은 평년보다 사나흘가량 늦은 이달 말부터 장마가 시작될 것이라는 게 기상청의 설명이다. 장마전선은 이후 한 달가량 한반도 중남부를 오르내리며 곳곳에 비를 뿌릴 전망이다. 최근 30년간 평균치에 따르면 중부지방의 장마 시작일은 6월24~25일이었으며 장마기간은 32일, 강수일수는 17.2일이었다.기상청은 올해 장마기간의 평균 강수량이 350~400㎜로 평년과 비슷하거나 적을 것으로 내다봤다. 브라질 월드컵 한국과 러시아의 경기가 열리는 18일 오전 서울은 대체로 구름이 많이 끼지만 비는 오지 않을 것으로 예상돼 거리 응원에는 지장이 없을 전망이다.',
'news_category': '종합',
'source': 'hankyung',
'guid': 'klue-mrc-v1_train_12759',
'is_impossible': False,
'question_type': 1,
'question': '북태평양 기단과 오호츠크해 기단이 만나 국내에 머무르는 기간은?',
'answers': {'answer_start': [478, 478], 'text': ['한 달가량', '한 달']}}
우리는 이 데이터들을 통해 할루시네이션이 일어나는 질문에 대한 답변의 정확도를 개선할 수 있을 것이다.
텍스트를 임베딩 벡터로 변환하기
from llama_index.core import Document, VectorStoreIndex
text_list = dataset[:100]['context']
documents = [Document(text=t) for t in text_list]
# 인덱스 만들기
index = VectorStoreIndex.from_documents(documents)
라이브러리를 불러오고, 다운로드하였던 데이터셋 중 앞에서 100개만 뽑아 그중 context만 가져온다. 이어서 Document 클래스에 text 인자로 이 context들을 전달하여 documents 리스트를 선언한다. 앞서 라마 인덱스 라이브러리에 대한 설명을 표면적으로 했는데, 다시 쉽게 말하자면 라마 인덱스는 아주 새로운 무언가가 아니다. 라마 인덱스는 임베딩을 하기 위해 OpenAI의 'text-embedding-ada-002' 모델을 쓰고, in-memory 방식의 벡터 데이터베이스를 사용하는, 그저 편의성을 제공해 주는 라이브러리인 것이다. 이어서 VectorStoreIndex 클래스의 from_documents() 메서드를 통해 documents 리스트 속 텍스트들을 임베딩 벡터로 변환하여 index에 저장한다.
검색 엔진 생성
print(dataset[0]['question']) # 북태평양 기단과 오호츠크해 기단이 만나 국내에 머무르는 기간은?
retrieval_engine = index.as_retriever(similarity_top_k=5, verbose=True)
response = retrieval_engine.retrieve(
dataset[0]['question']
)
print(len(response)) # 출력 결과: 5
print(response[0].node.text)
이어서 질문에 대한 요청과 답이 어떻게 나오는지 보자. 첫 번째 데이터의 요청을 넣었을 때, .as_retriever() 메서드는 이 요청에 가까운 5개의 기사를 반환해 주는 검색 엔진을 생성해 준다. 이 검색 엔진에 .retrieve() 메서드를 통해 요청에 대한 5개의 context를 얻을 수 있다. 우리는 당연히 해당 context에 있던 예시 질문으로 유사도를 검색했기에 가장 유사도가 큰 context는 아까 살펴봤던 context가 될 것이다.
쿼리 엔진 생성
query_engine = index.as_query_engine(similarity_top_k=1)
response = query_engine.query(
dataset[0]['question']
)
print(response)
좋다. 이제 RAG 모델이 올바르게 작동하는지 보기 위해 쿼리 엔진을 생성해 보았다. 쿼리 엔진에 요청으로 첫 번째 데이터의 요청을 넣은 결과는 아래와 같다.
장마전선에서 내리는 비를 뜻하는 장마는 고온다습한 북태평양 기단과 한랭 습윤한 오호츠크해 기단이 만나 형성되며 국내에 한 달가량 머무르게 됩니다.
이처럼 우리는 쿼리가 자신과 유사도가 높은 정보를 벡터 데이터베이스에서 찾고, 이를 쿼리와 합쳐 최적의 답변을 내놓는 과정을 진행해 보았다. 뭔가 많이 생략되어 있는 것 같지 않은가? 맞다. 벡터 데이터베이스에서 검색하는 rertriever, 검색 결과를 사용자의 쿼리와 통합하기 위한 response_synthesizer, 그리고 이 둘을 query engine에 전달하여 RAG를 수행하는 과정을 따로 해도 되지만, 라마 인덱스를 사용하면 위와 같은 코드만으로도 RAG를 구현할 수 있다. 하지만 세부적인 조정을 하고 싶다면 아래 코드를 참조하면 된다.
from llama_index.core import (
VectorStoreIndex,
get_response_synthesizer,
)
from llama_index.core.retrievers import VectorIndexRetriever
from llama_index.core.query_engine import RetrieverQueryEngine
from llama_index.core.postprocessor import SimilarityPostprocessor
# 검색을 위한 Retriever 생성
retriever = VectorIndexRetriever(
index=index,
similarity_top_k=1,
)
# 검색 결과를 질문과 결합하는 synthesizer
response_synthesizer = get_response_synthesizer()
# 위의 두 요소를 결합해 쿼리 엔진 생성
query_engine = RetrieverQueryEngine(
retriever=retriever,
response_synthesizer=response_synthesizer,
node_postprocessors=[SimilarityPostprocessor(similarity_cutoff=0.7)],
)
'AI' 카테고리의 다른 글
| [LLM] 임베딩 모델로 데이터 의미 압축하기 (1) - 텍스트 임베딩 이해하기 (0) | 2024.11.16 |
|---|---|
| [LLM] LLM Cache로 효율성 확보하기 with ChromaDB (0) | 2024.11.13 |
| [LLM] 트랜스포머 구조 파헤치기 (4) - 인코더와 디코더 (0) | 2024.11.08 |
| [LLM] 트랜스포머 구조 파헤치기 (3) - 정규화와 피드 포워드 층 (0) | 2024.11.07 |
| [LLM] 트랜스포머 구조 파헤치기 (2) - 어텐션 (Attention) 이해하기 (2) | 2024.11.04 |