ChatGPT를 내가 개발하고 있는 서비스에서 호출해서 사용하려면 어떻게 해야 할까? 현재 OpenAI에서는 Curl, Node.js 그리고 Python 이렇게 세 종류의 API를 제공하고 있으며, 이 중 Python에서 사용하는 방법을 정리해보려 한다. 그전에 앞서 OpenAI는 내가 적용해보려 하는 태스크를 간단히 테스트해 볼 수 있는 Playground를 제공해 주는데, 이에 대해 자세히 알아보자.
[LLM] OpenAI API (1) - API key 발급하기
ChatGPT를 내가 개발하고 있는 서비스에서 호출해서 사용하려면 어떻게 해야 할까? 현재 OpenAI에서는 Curl, Node.js 그리고 Python 이렇게 세 종류의 API를 제공하고 있으며, 이 중 Python에서 사용하는 방
dusanbaek.tistory.com
Playground
API Key를 발급하고 나서는 아래와 같이 웹사이트에서 제공하는 Playground에서 여러 설정들을 조정해 가며 테스트가 가능하다. 여기서 설정하고 프로젝트 별로 저장도 가능하지만, 여기서의 설정을 그대로 가져와서 바로 적용하는 방법은 없고 개발할 때에는 코드를 통해 작성해주어야 한다는 점은 단점으로 볼 수 있겠다.
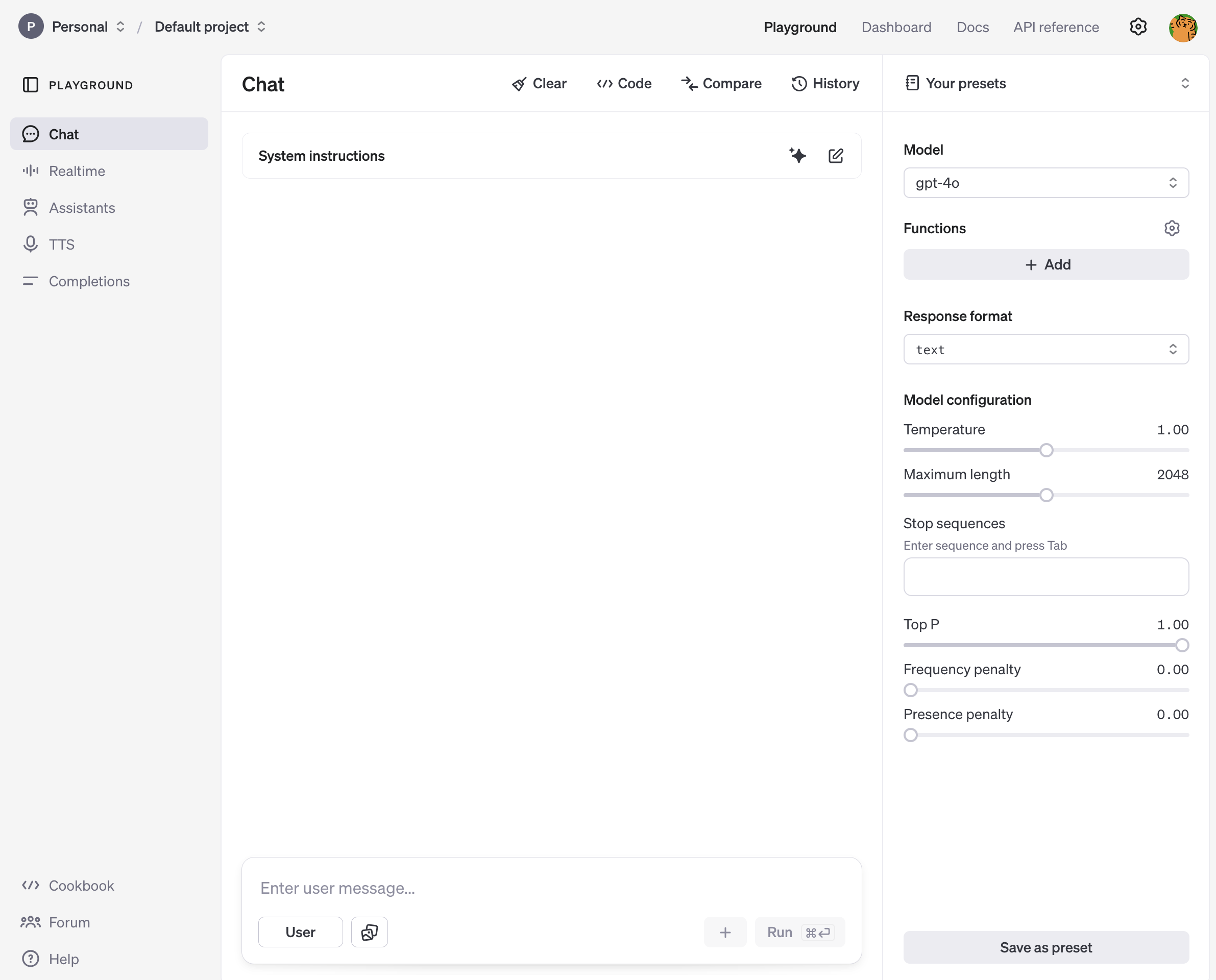
프로젝트별 위와 같은 화면이 구성되는데, 여기서 오른쪽 패널에 있는 설정들은 조절해 볼 수 있다. 하나씩 살펴보자.
Model

OpenAI에서 개발한 여러 모델을 선택할 수 있다. 테스트에서도 과금이 되니 GPT-3.5-turbo와 같은 가장 싼 모델을 이용하는 것을 추천한다. 물론 이미지 생성이나 첨부파일을 넣어야 하는 경우에는 좀 더 최신 모델이 필요하다. 입력값과 출력값이 뭔지에 따라 최소로 요구되는 모델이 존재한다.
Functions
이어서 Function을 추가해 보자.
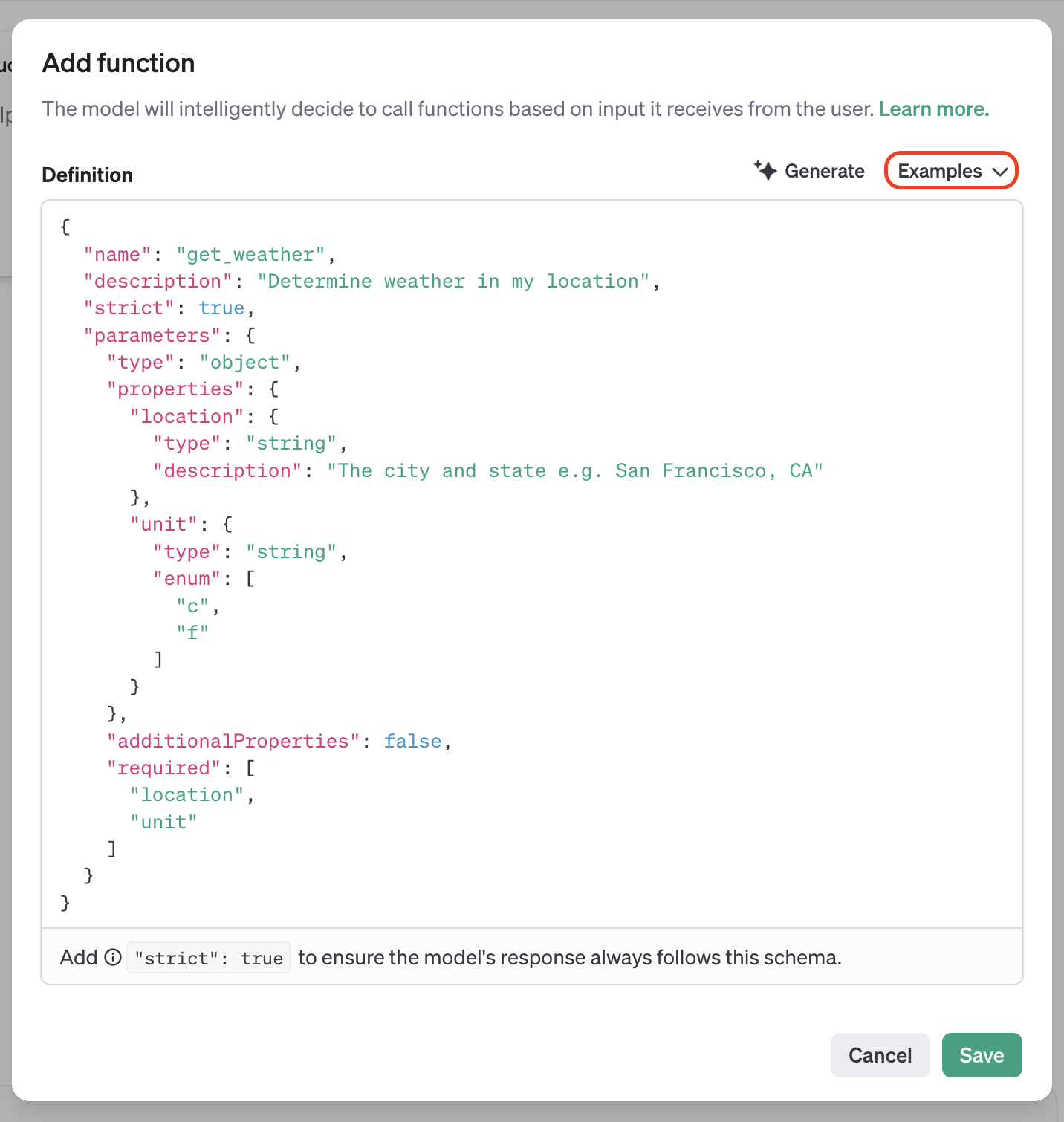
OpenAI에서는 튜토리얼로 get_weather()와 get_stock_price() 예시 코드를 제공하는데, json 구조에서 각 값의 뜻은 다음과 같다.
name - 함수의 이름
description - 모델이 이 함수를 알아볼 수 있게 설명해 주는 글
strict - boolean 값인데, 만약 이것이 true라면 아래 기술할 parameter값이 제대로 제공되지 않았을 때 함수가 실행되지 않는다.
parameters - 이곳에서 파라미터를 정의한다.
type - 파라미터의 타입을 정의하는데, 예시에서는 객체로 정의하였다.
properties - 이곳에 파라미터의 이름과 타입, 그리고 설명을 적는다. 위 예시에서는 위치와 기온의 단위가 프로퍼티가 된다.
additionalProperties - boolean 값인데, 만약 이것이 true라면 다른 프로퍼티 값을 추가로 제공할 수 있다.
required - 필수 매개변수를 지정한다; 이곳에 적히면 프로퍼티가 누락되었을 때 해당 함수가 실행되지 않는다.
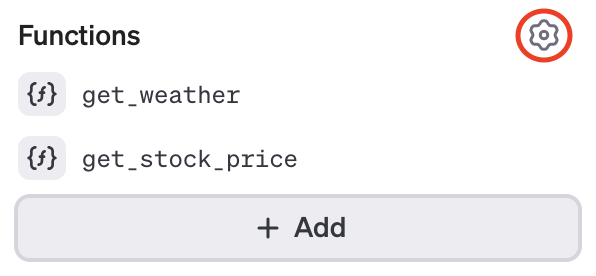

위와 같이 두 Function을 동시에 추가하는 것도 물론 가능이다. 메시지를 입력하면, 메시지에서 원하는 정보를 찾기 위해 모델이 알아서 Functions를 참조하므로, 우린 그저 여러 Function을 추가해 주면 된다. 설정을 누르면 parallel_tool_calls 여부를 체크하는 란이 존재하는데, 이를 설정하면 한 메시지에서 두 Function을 병렬로 참조할 수 있게 한다. 예를 들어 날씨와 주식 가격을 동시에 물어보는 경우, 두 Function이 모두 참조되는 것이다.
Response Format
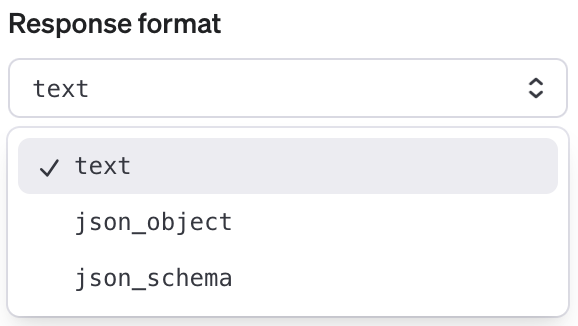
모델의 답변 형식을 지정할 수 있다. 줄글 형식과 json 구조로 생성할 수 있는데, schema는 좀 더 엄격한 구조화가 된 json 구조라고 생각하면 된다.
Model configuration
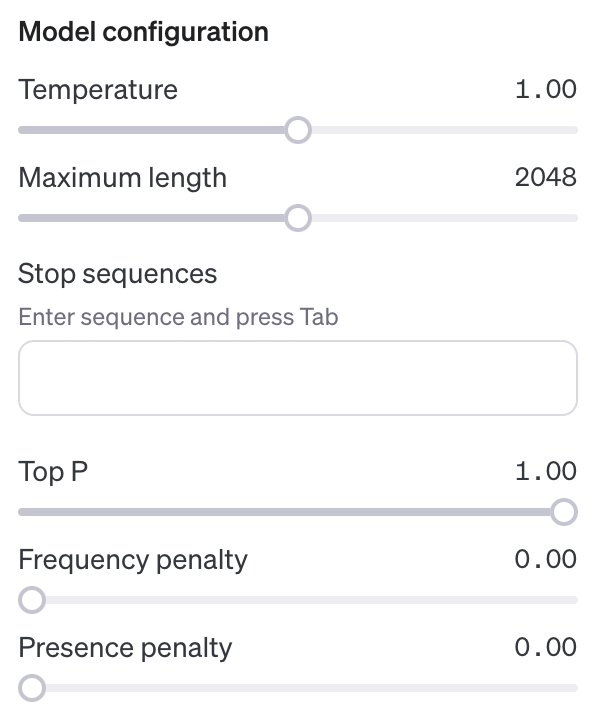
마지막으로 Model configuration이다. 각각의 설정 요소는 다음과 같은 의미를 지니고 있다.
Temperature - 생성할 텍스트의 온도를 뜻한다. 굉장히 추상적인데, 쉽게 말해 온도가 올라가면 문장의 창의성이 올라간다. 낮아지면 뻔한 대답을 내놓는다. 기본값은 1이다.
Maximum length - 생성할 텍스트의 최대 길이를 뜻한다. 이 값이 클수록 더 긴 텍스트를 생성할 수 있고, 최댓값은 4096이다.
Stop sequences - 생성 텍스트를 중간에 멈추게 하는 sequence를 설정해 두면, 텍스트를 생성하다 그 위치에서 생성을 중단한다. 여러 Stop sequence를 가질 수 있다.
Top P - 응답에서 확률 분포를 제한하는 옵션이다. 이 값이 크면 클수록 낮은 확률의 단어들이 포함될 가능성이 증가하므로, 문장을 다채롭게 구성하고 싶으면 값을 크게 설정하면 된다.
Frequency penalty - 단어의 빈도를 조절한다. 값이 높을수록 전체 생성 텍스트에서 단어들의 등장 빈도가 줄어든다.
Presence penalty - 단어의 등장을 조절한다. 같은 의미의 단어가 있다면 값이 높을수록 그 단어로 대체되어 보일 확률이 증가한다.
Simulation

자 이제 메시지를 입력해 보자. 샌프란시스코의 날씨를 섭씨로 알려달라고 물으면,
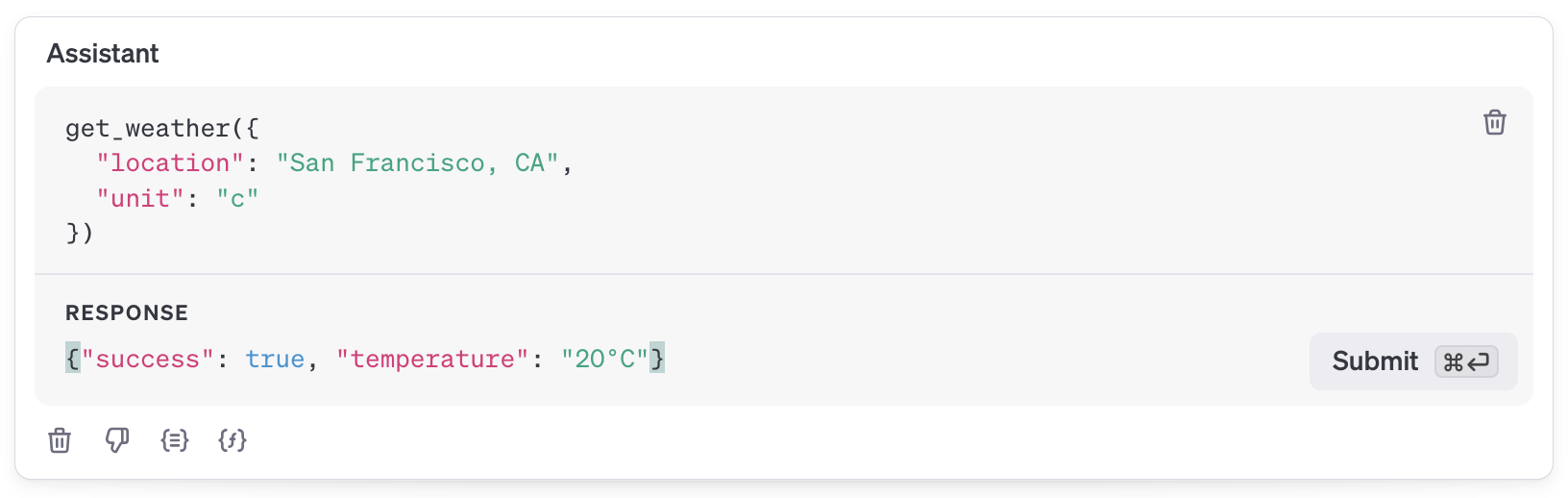
모델은 get_weather() Function을 참조하여 위치와 단위를 추론할 수 있다. Response는 내가 직접 작성하였는데, 그 이유는 Playground에서 날씨 api를 참조할 수 없기 때문이다. 실제 상황에서는 모델이 판단한 결과를 바탕으로 답변을 제공하지만 Playground 환경에서는 사용자가 임의로 응답의 성공 여부와 답변을 작성하여 Submit 해야 한다. 그 결과

내가 작성한 데이터를 기반으로 답변을 작성해 준다. 만약 필수 프로퍼티를 제대로 제공하지 않는다면,
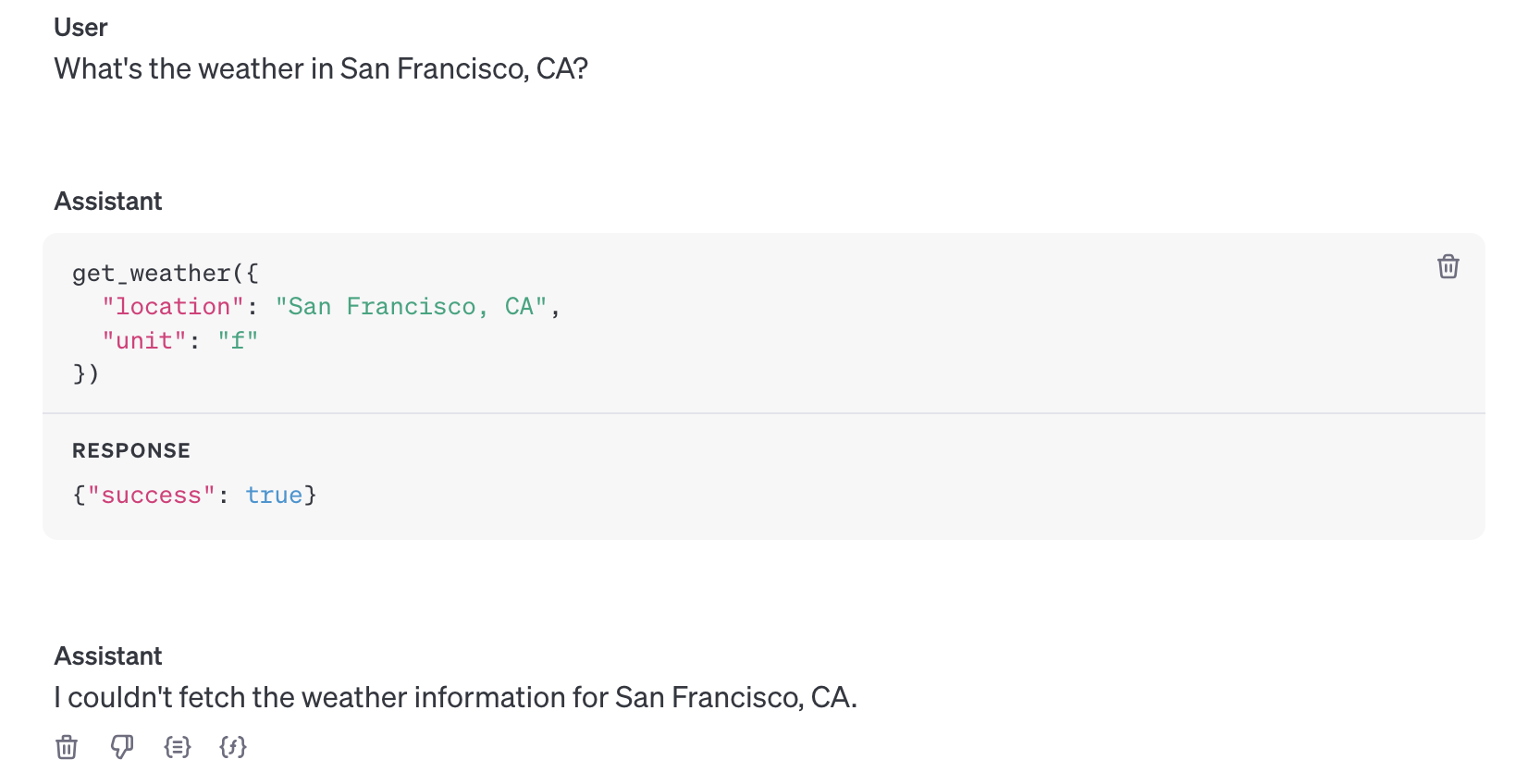
단위를 알아서 추론하게 되고, 위와 같이 답변에 데이터도 수동으로 제공하지 않는다면 원하는 답변을 얻을 수 없게 됨을 확인할 수 있다.
[LLM] OpenAI API (3) - 파이썬 코드로 호출해 보기
ChatGPT를 내가 개발하고 있는 서비스에서 호출해서 사용하려면 어떻게 해야 할까? 현재 OpenAI에서는 Curl, Node.js 그리고 Python 이렇게 세 종류의 API를 제공하고 있으며, 이 중 Python에서 사용하는 방
dusanbaek.tistory.com
'AI' 카테고리의 다른 글
| [LLM] 트랜스포머 구조 파헤치기 (2) - 어텐션 (Attention) 이해하기 (3) | 2024.11.04 |
|---|---|
| [LLM] OpenAI API (3) - 파이썬 코드로 호출해 보기 (2) | 2024.11.02 |
| [LLM] OpenAI API (1) - API key 발급하기 (0) | 2024.10.30 |
| [LLM] 트랜스포머 구조 파헤치기 (1) - 텍스트를 임베딩 (Embedding)으로 변환하기 (4) | 2024.10.24 |
| [EDA] 탐색적 데이터 분석 with Python (2) (4) | 2024.09.28 |